
티스토리 뷰
-
DB 기반으로 스케줄러 간의 Clustering 기능을 제공한다
-
In-memory Job Scheduler도 제공한다
-
여러 기본 Plug-in을 제공한다
-
Clustering 기능을 제공하지만, 단순한 random 방식이라서 완벽한 Cluster 간의 로드 분산은 안된다
-
어드민 UI을 제공하지 않는다
-
스케줄링 실행에 대한 History는 보관하지 않는다
-
Fixed Delay 타입을 보장하지 않으므로 추가 작업이 필요하다. (Fixed Delay: 이전 수행이 종료된 시점부터 delay 후에 재호출)
Fixed Delay가 안된다고?? 테스트 해보자. (구현관련 설명은 Quartz 2.2.2 QuickStartGuide 참고)
public class MyObject implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
JobKey jobKey = jobExecutionContext.getJobDetail().getKey();
System.out.println(jobKey);
System.out.println("my shceduler is running!");
System.out.println("the time now is " + new Date());
try {
for (int i = 0; i < 3; i++) {
System.out.println("Sleep " + i + " " +Thread.currentThread().getName());
Thread.sleep(1000);
}
}catch(Exception e) {
System.out.println(e);
}
}
}public class MyMainScheduler {
public static void main(String[] args) throws SchedulerException {
JobDetail jobDetail = JobBuilder.newJob(MyObject.class)
.withIdentity("job1","group1")
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "group1")
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(2)
.repeatForever())
.build();
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start();
}
}#quartz.properties
org.quartz.scheduler.instanceName = MyScheduler
org.quartz.threadPool.threadCount = 20
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore# log4j.properties
log4j.rootLogger=DEBUG, stdout
# quartz logging
log4j.logger.org.quartz=DEBUG
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-3p [%t] %c{3} %M:%L - %m%n
로그 결과

그렇군. 처음 job1 이 종료된 후, 2초후에 잡이 다시 시작되는게 아니라 그냥 2초 단위로 시작되는군.
잠깐! 지금은 쿼츠 스레드가 20개로 지정되있어서 이렇게 스레드 변경해서 2초마다 그냥 시작된다지만 최대 스레드가 한개라면???

오호... 그렇군 2초후에 잡이 시작되려고 했는데 이미 돌아가고 있는 잡이 있어서 시작되려는 잡이 홀딩되고, 앞의 잡이 끝나자마자 실행되는군!
쿼츠는 수천개까지 잡을 스케줄링 할 수 있다고 한다.
진짜로??? 가볍게 2000개만 만들어서 테스트 해보자.
public static void main(String[] args) throws SchedulerException {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
for (int i=0; i<2000; i++) {
JobDetail jobDetail = JobBuilder.newJob(MyObject.class)
.withIdentity("job" + i, "group1")
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger"+i, "group1")
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(2)
.repeatForever())
.build();
scheduler.scheduleJob(jobDetail, trigger);
}
scheduler.start();
}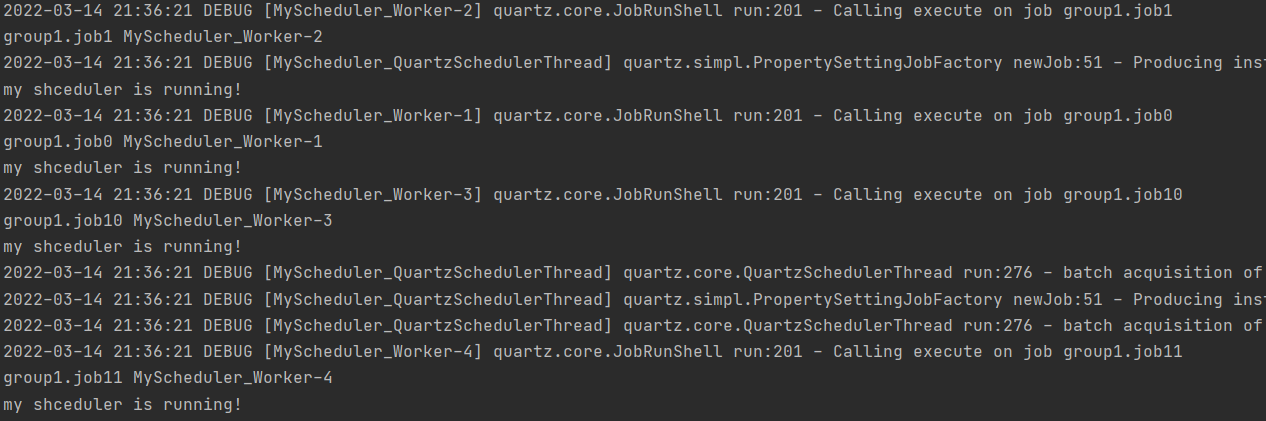
아니 이럴수가?! 1, 0, 10, 11 순서로 실행되다니?
몇번 실행해봤는데 딱히 스케줄러에 잡이 등록되는 규칙같은건 없는듯 하다. 이래서 그냥 라운드로빈 방식이고, 완벽하게 분산하는 건 어렵다고 적혀있던 거군?
분명 job0, job1, job2 순서대로 등록했을 텐데 job1, job0, job10 순서대로 시작된다라.
여기서 우리는 스레드 20개가 전부 꽉 차서 일을 하고 있을 경우, 동일 스레드 상에서 job 2가 우연치 않게 매우 느린 job1 뒤에 스케줄링 된 경우 job2 는 엄청나게 지연될 것이라는 것을 추측할 수 있다.
이걸 해결하려면... 음... 쿼츠 스케줄링에 등록된 잡들중에 지연되는 잡이 있으면 그 이후의 잡은 해당 스레드에서 빼서 지연되고 있지 않은 스레드에 다시 넣어줄 필요가 있다. 즉 주기적으로 현재 동작중인 잡이 몇분 정도 지났는지 파악을 하면서 지연되고 있는지를 체크해야한다는 것.
일단 현재 동작중인 잡 이후에 실행될 잡을 스케줄링에서 동적으로 뺄 수 있는지 알아봐야겠다.
공식문서를 참고하자
http://www.quartz-scheduler.org/documentation/quartz-2.2.2/cookbook/UnscheduleJob.html
Cookbook
www.quartz-scheduler.org
'JAVA' 카테고리의 다른 글
| [JAVA] 상속의 목적 (0) | 2020.04.16 |
|---|---|
| [JAVA] static 이란? (1) | 2020.04.09 |
| [Java 함수] StringBuilder (0) | 2020.02.15 |